For much of the past year, I have been working with Hexvarium. Based in Atherton, California, the company builds and manages fiber-optic networks. At present, they have a handful of networks in the Bay Area but have plans to expand across the US.
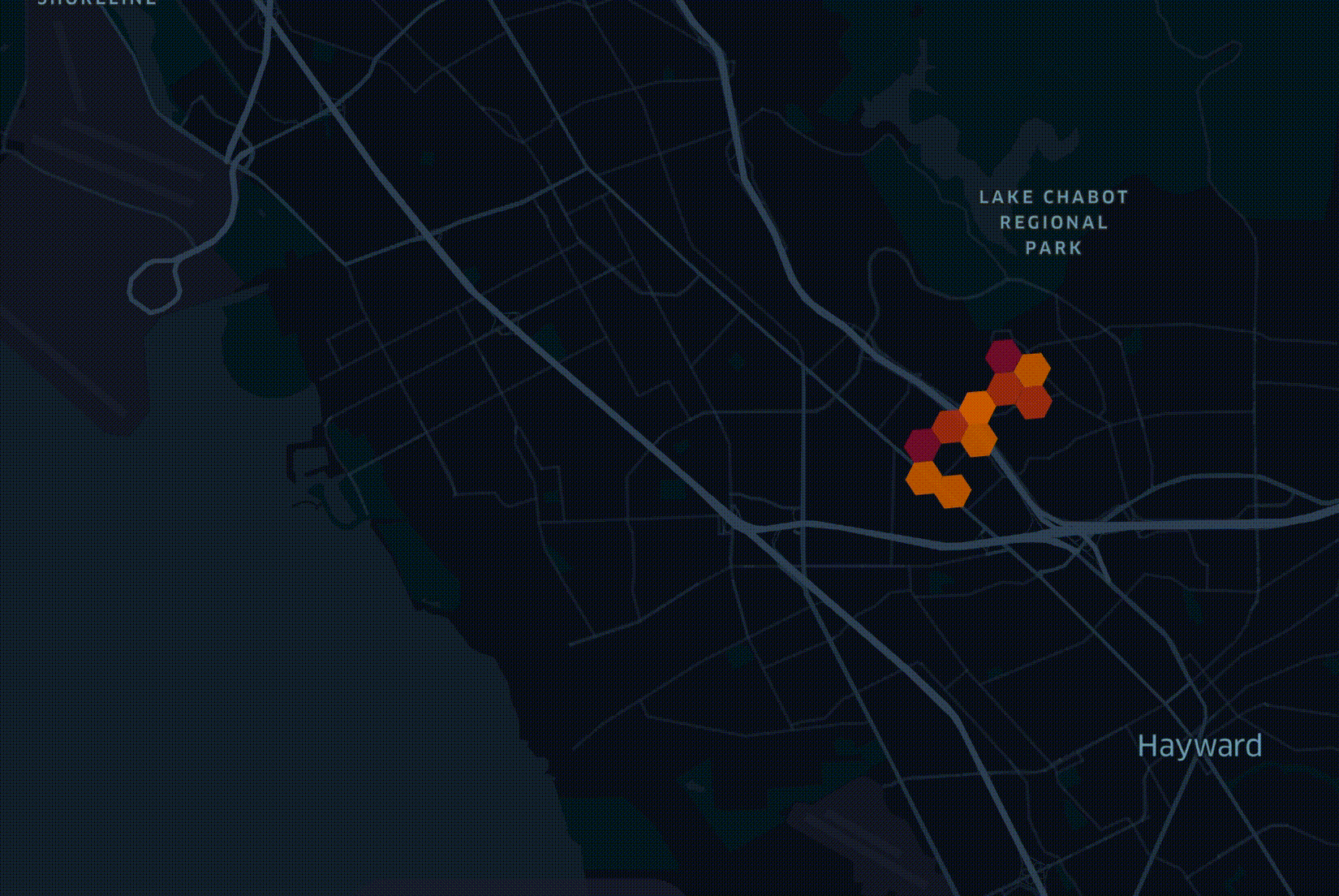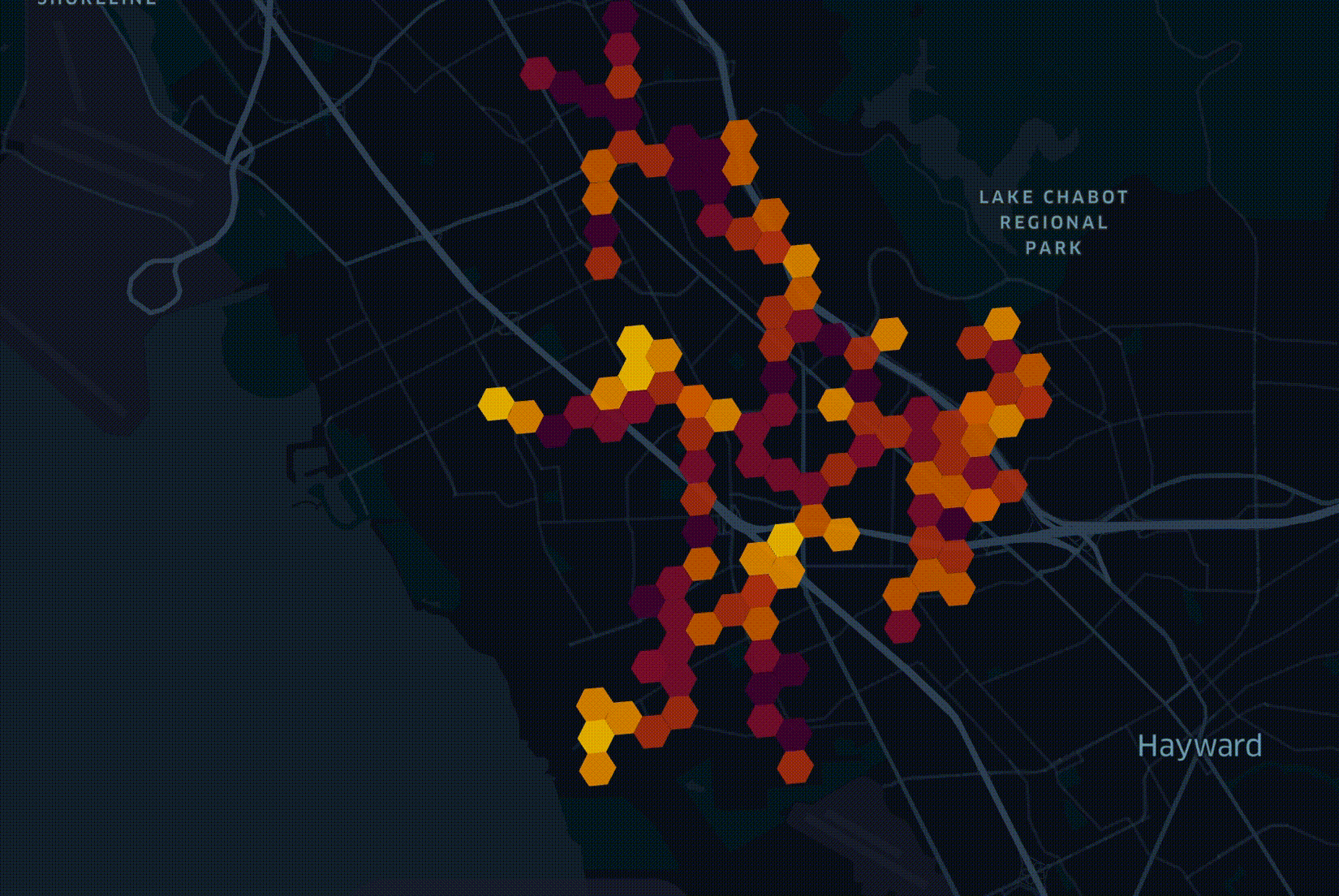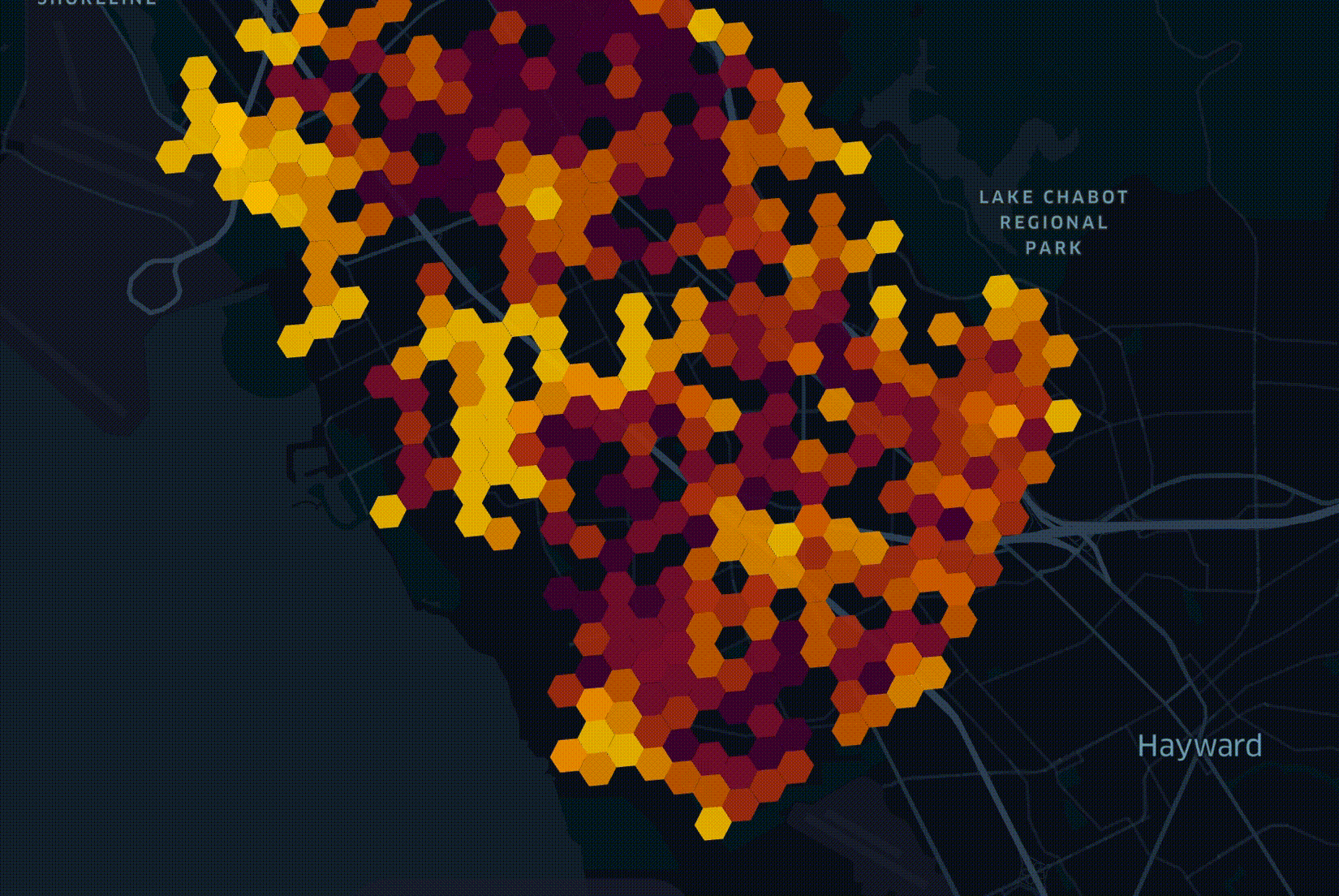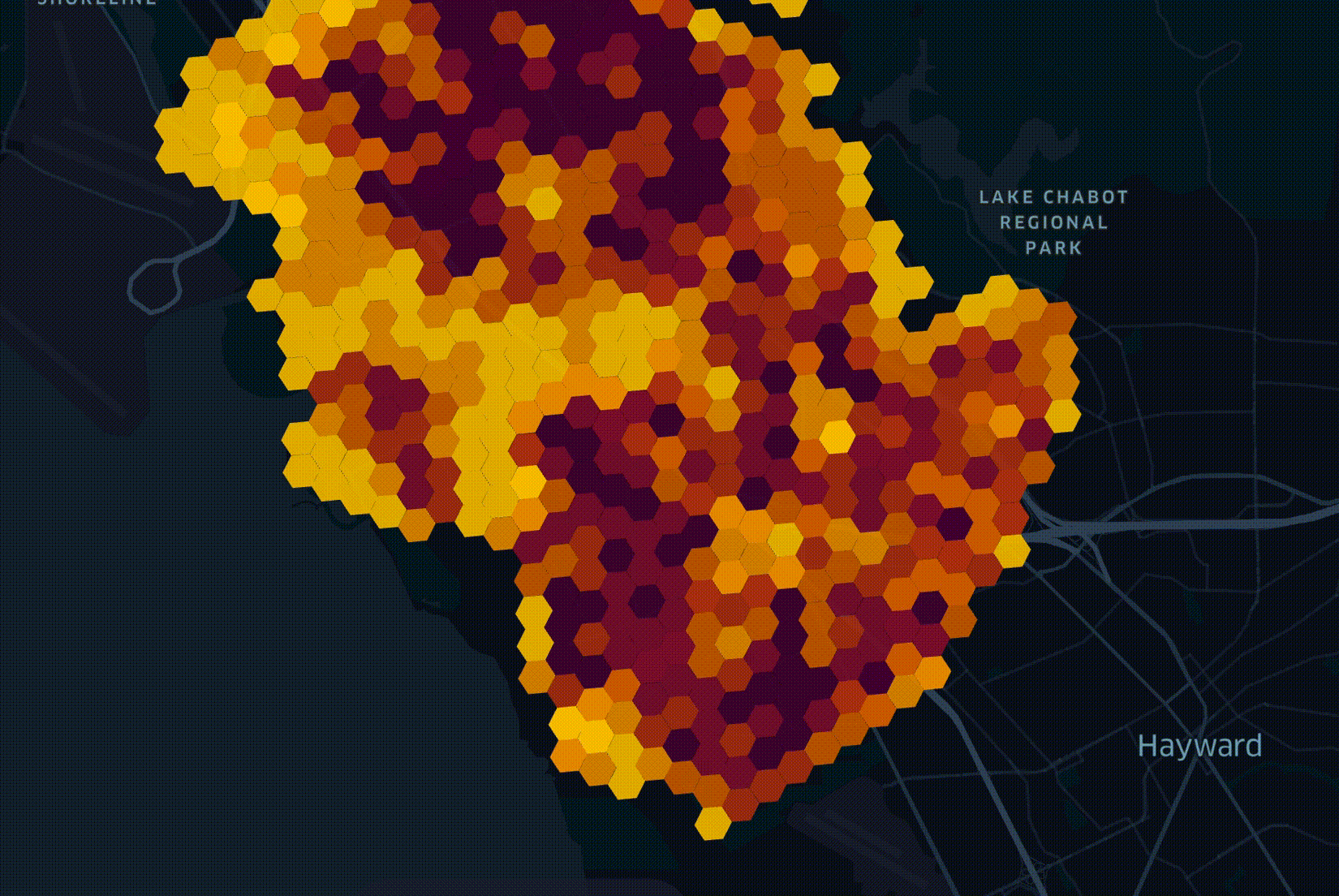
My role is to manage a data platform that holds 30 billion records from some 70 sources of information. This data is used by engineers working on optimal fiber-optic network rollout plans using LocalSolver. Below is a figurative example of one of these plans.
Our data platform is largely made up of PostGIS, ClickHouse and BigQuery. Data arrives in a wide variety, but often never optimal formats. We then shape and enrich the data, often with PostGIS or ClickHouse, before shipping it off to BigQuery. Engineers working with LocalSolver will then source their data from a pristine and up-to-date version on BigQuery.
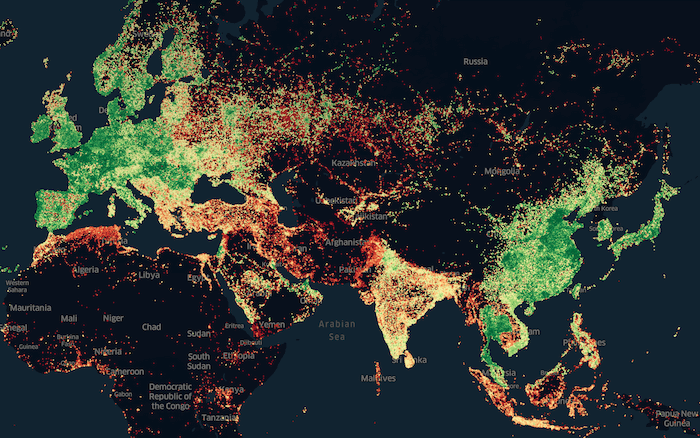
Analysis feeds the imagination of the engineers so we're often visualising data we've received using Unfolded. Below is a visualisation we produced of Ookla's Speedtest from last summer. We grouped records by H3's zoom level 9 and took the highest average download speed from each hexagon, plotting them on the globe.
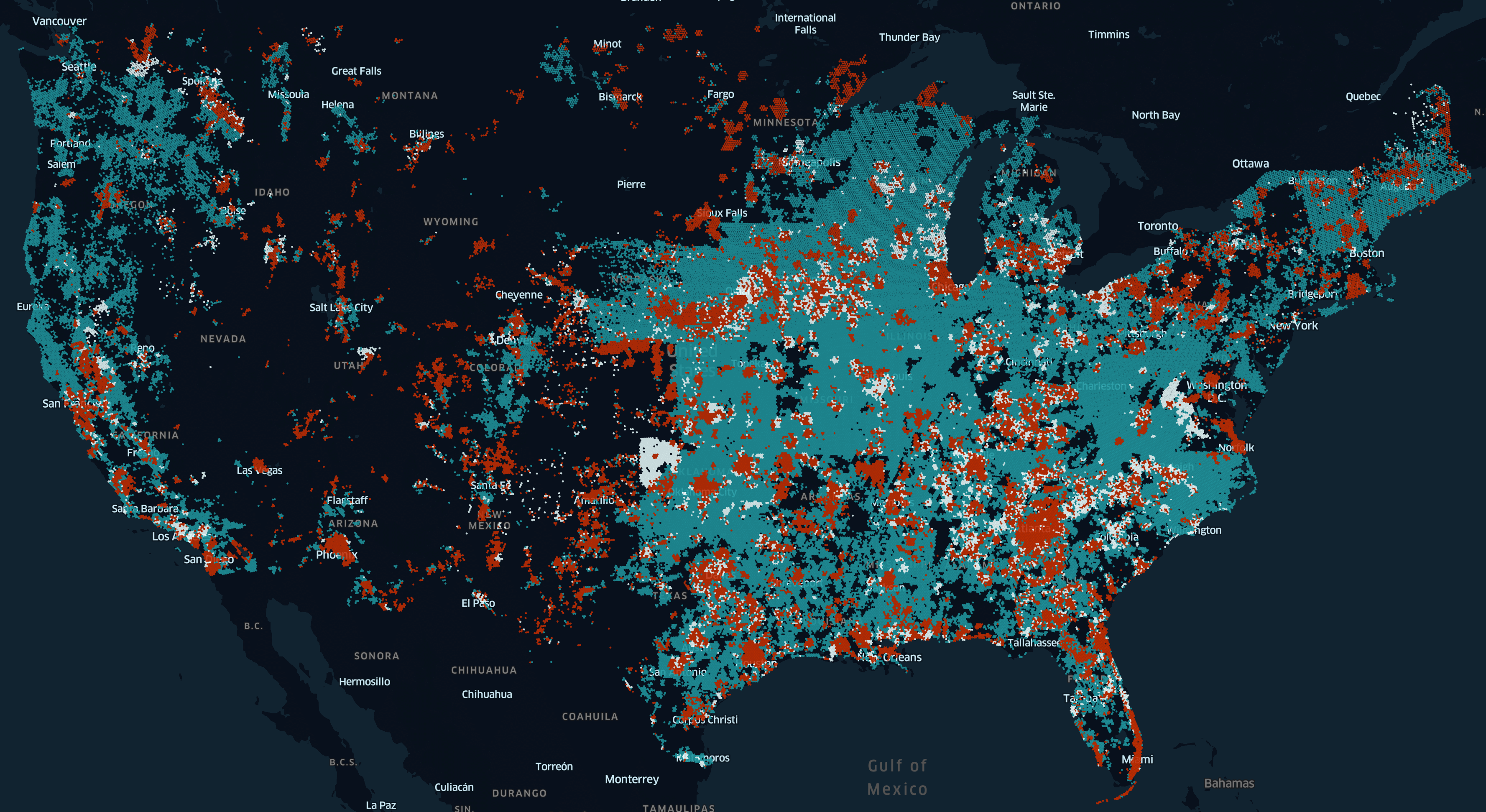
Below is another visualisation we produced showing the difference in top broadband speeds between June and November last year. These were reported to the FCC by broadband providers across the US.
In recent months, I've been exploring ways to both increase the throughput of our pipeline and find ways of reducing engineering labour. One of the tools I've been examining to help me with this is DuckDB.
DuckDB's Features of Interest
DuckDB is primarily the work of Mark Raasveldt and Hannes Mühleisen. It's made up of a million lines of C++ and runs as a stand-alone binary. Development is very active with the commit count on its GitHub repo doubling nearly every year since it began in 2018. DuckDB uses PostgreSQL's SQL parser, Google’s RE2 regular expression engine and SQLite's shell.
SQLite supports five data types, NULL, INTEGER, REAL, TEXT and BLOB. I was always frustrated by this as working with time would require transforms in every SELECT statement and not being able to describe a field as a boolean meant analysis software couldn't automatically recognise and provide specific UI controls and visualisations of these fields.
Thankfully, DuckDB supports 25 data types out of the box and more can be added via extensions. Work is underway on an extension which will port Paul Ramsey's PostGIS geospatial functionality to DuckDB. Isaac Brodsky, a Principal Engineer at Foursquare, Unfolded's parent company, has also recently published an H3 extension for DuckDB. And although nothing has been published yet, there are efforts underway to embed GDAL via its Arrow-based interface into DuckDB.
A min-max index is created for every column segment in DuckDB. This index type is how most OLAP database engines answer aggregate queries so quickly. Parquet and JSON extensions are shipped in the official build and their usage is well documented. Both Snappy and ZStandard compression are supported for Parquet files.
DuckDB's documentation is well-organised and refreshingly terse with examples next to most descriptions.
DuckDB, Up & Running
The official release of DuckDB doesn't contain the Geospatial and H3 extensions used in this post so I'll compile DuckDB with these extensions.
The commands below were run on an e2-standard-4 instance on Google Cloud running Ubuntu 20 LTS. This VM contains 4 vCPUs and 16 GB of RAM. It was run in the Los Angeles-based us-west2-b region and has a 100 GB balanced persistent disk. It cost $0.18 / hour to run.
The following will install some prerequisites used in this post.
$ sudo apt update
$ sudo apt install \
awscli \
build-essential \
libssl-dev \
pigz \
unzip
CMake version 3.20+ is required to compile the H3 extension so I'll build that first.
$ cd ~
$ wget -c https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0.tar.gz
$ tar -xzf cmake-3.20.0.tar.gz
$ cd cmake-3.20.0
$ ./bootstrap --parallel=$(nproc)
$ make -j$(nproc)
$ sudo make install
The following will build both DuckDB and an H3 extension for it. The geo extension is pinned to DuckDB's c817201 commit so I'll pin the H3 extension to this as well.
$ git clone https://github.com/isaacbrodsky/h3-duckdb ~/duckdb_h3
$ cd ~/duckdb_h3
$ git submodule update --init
$ cd duckdb
$ git checkout c817201
$ cd ..
$ CMAKE_BUILD_PARALLEL_LEVEL=$(nproc) \
make release
The following will build an extension which brings parts of PostGIS' functionality to DuckDB.
$ git clone https://github.com/handstuyennn/geo ~/duckdb_geo
$ cd ~/duckdb_geo
$ git submodule init
$ git submodule update --recursive --remote
$ mkdir -p build/release
$ cmake \
./duckdb/CMakeLists.txt \
-DEXTERNAL_EXTENSION_DIRECTORIES=../geo \
-DCMAKE_BUILD_TYPE=RelWithDebInfo \
-DEXTENSION_STATIC_BUILD=1 \
-DBUILD_TPCH_EXTENSION=1 \
-DBUILD_PARQUET_EXTENSION=1 \
-B build/release
$ CMAKE_BUILD_PARALLEL_LEVEL=$(nproc) \
cmake --build build/release
I'll create a shell file that will launch the DuckDB binary with support for the unsigned extensions.
$ echo "$HOME/duckdb_geo/build/release/duckdb -unsigned \$@" \
| sudo tee /usr/sbin/duckdb
$ sudo chmod +x /usr/sbin/duckdb
I'll set up DuckDB's configuration file to load both extensions by default.
$ vi ~/.duckdbrc
.timer on
LOAD '/home/mark/duckdb_h3/build/release/h3.duckdb_extension';
LOAD '/home/mark/duckdb_geo/build/release/extension/geo/geo.duckdb_extension';
I'll launch DuckDB and test that the extensions are working.
$ duckdb
SELECT h3_cell_to_parent(CAST(586265647244115967 AS ubigint), 1) test;
┌────────────────────┐
│ test │
│ uint64 │
├────────────────────┤
│ 581764796395814911 │
└────────────────────┘
SELECT ST_MAKEPOINT(52.347113, 4.869454) test;
┌────────────────────────────────────────────┐
│ test │
│ geography │
├────────────────────────────────────────────┤
│ 01010000001B82E3326E2C4A406B813D26527A1340 │
└────────────────────────────────────────────┘
I find it helpful that by default, the data type is displayed below each field name.
The Ookla Speedtest Dataset
Ookla publish their Speedtest data to AWS in Parquet format. Below I'll download the 2022 dataset for mobile devices.
$ aws s3 sync \
--no-sign-request \
s3://ookla-open-data/parquet/performance/type=mobile/year=2022/ \
./
The folder paths structure is meant for Apache Hive partitioning support. I'll just be using four of the Parquet files so I'll move them into the same folder.
$ mv quarter\=*/*.parquet ./
Below are the sizes for each of the files. In total, they contain 15,738,442 rows of data.
$ ls -lht *.parquet
173M 2022-10-01_performance_mobile_tiles.parquet
180M 2022-07-01_performance_mobile_tiles.parquet
179M 2022-04-01_performance_mobile_tiles.parquet
174M 2022-01-01_performance_mobile_tiles.parquet
Below is the schema used in these Parquet files.
$ echo "SELECT name,
type,
converted_type
FROM parquet_schema('2022-10*.parquet');" \
| duckdb
┌────────────┬────────────┬────────────────┐
│ name │ type │ converted_type │
│ varchar │ varchar │ varchar │
├────────────┼────────────┼────────────────┤
│ schema │ BOOLEAN │ UTF8 │
│ quadkey │ BYTE_ARRAY │ UTF8 │
│ tile │ BYTE_ARRAY │ UTF8 │
│ avg_d_kbps │ INT64 │ INT_64 │
│ avg_u_kbps │ INT64 │ INT_64 │
│ avg_lat_ms │ INT64 │ INT_64 │
│ tests │ INT64 │ INT_64 │
│ devices │ INT64 │ INT_64 │
└────────────┴────────────┴────────────────┘
Ookla have used Snappy compression on each column. DuckDB is able to pull diagnostics on how the data is laid out and provide statistical information on each column. Below are the tile column's details.
$ echo ".mode line
SELECT *
EXCLUDE (stats_min_value,
stats_max_value)
FROM parquet_metadata('2022-10-01_*.parquet')
WHERE path_in_schema = 'tile'
AND row_group_id = 0;" \
| duckdb
file_name = 2022-10-01_performance_mobile_tiles.parquet
row_group_id = 0
row_group_num_rows = 665938
row_group_num_columns = 7
row_group_bytes = 31596007
column_id = 1
file_offset = 24801937
num_values = 665938
path_in_schema = tile
type = BYTE_ARRAY
stats_min =
stats_max =
stats_null_count = 0
stats_distinct_count =
compression = SNAPPY
encodings = PLAIN_DICTIONARY, PLAIN, RLE, PLAIN
index_page_offset = 0
dictionary_page_offset = 3332511
data_page_offset = 3549527
total_compressed_size = 21469426
total_uncompressed_size = 124569336
Importing Parquet
I can import all four Parquet files into DuckDB using a single SQL statement. This will add an additional column stating the filename each row of data originated from. The 706 MB of Parquet and the additional column turned into a 1.4 GB DuckDB file.
$ echo "CREATE TABLE mobile_perf AS
SELECT *
FROM read_parquet('*.parquet',
filename=true);" \
| duckdb ~/ookla.duckdb
Alternatively, using DuckDB's HTTPFS extension, I can load the Parquet files directly from S3.
$ echo "INSTALL httpfs;
CREATE TABLE mobile_perf AS
SELECT *
FROM parquet_scan('s3://ookla-open-data/parquet/performance/type=mobile/year=2022/*/*.parquet',
FILENAME=1);" \
| duckdb ~/ookla.duckdb
If it isn't already present, the HTTPFS extension will be downloaded and installed automatically. Keep in mind, sometimes the builds aren't ready yet and you may see the following:
Error: near line 1: IO Error: Failed to download extension "httpfs" at URL "http://extensions.duckdb.org/7813eea926/linux_amd64/httpfs.duckdb_extension.gz"
Extension "httpfs" is an existing extension.
Are you using a development build? In this case, extensions might not (yet) be uploaded.
The DuckDB Table Structure
Below is the table schema DuckDB automatically put together.
$ echo '.schema --indent' \
| duckdb ~/ookla.duckdb
CREATE TABLE mobile_perf(
quadkey VARCHAR,
tile VARCHAR,
avg_d_kbps BIGINT,
avg_u_kbps BIGINT,
avg_lat_ms BIGINT,
tests BIGINT,
devices BIGINT,
filename VARCHAR
);;
Below is an example record.
$ echo '.mode line
SELECT *
FROM mobile_perf
LIMIT 1' \
| duckdb ~/ookla.duckdb
quadkey = 0022133222330023
tile = POLYGON((-160.043334960938 70.6363054807905, -160.037841796875 70.6363054807905, -160.037841796875 70.6344840663086, -160.043334960938 70.6344840663086, -160.043334960938 70.6363054807905))
avg_d_kbps = 15600
avg_u_kbps = 14609
avg_lat_ms = 168
tests = 2
devices = 1
filename = 2022-10-01_performance_mobile_tiles.parquet
Below are the compression schemes used in each of the fields' first segments in the first row-group.
$ echo "SELECT column_name,
segment_type,
compression,
stats
FROM pragma_storage_info('mobile_perf')
WHERE row_group_id = 0
AND segment_id = 0
AND segment_type != 'VALIDITY';" \
| duckdb ~/ookla.duckdb
┌─────────────┬──────────────┬─────────────┬───────────────────────────────────┐
│ column_name │ segment_type │ compression │ stats │
│ varchar │ varchar │ varchar │ varchar │
├─────────────┼──────────────┼─────────────┼───────────────────────────────────┤
│ quadkey │ VARCHAR │ FSST │ [Min: 00221332, Max: 02123303, … │
│ tile │ VARCHAR │ FSST │ [Min: POLYGON(, Max: POLYGON(, … │
│ avg_d_kbps │ BIGINT │ BitPacking │ [Min: 1, Max: 3907561][Has Null… │
│ avg_u_kbps │ BIGINT │ BitPacking │ [Min: 1, Max: 917915][Has Null:… │
│ avg_lat_ms │ BIGINT │ BitPacking │ [Min: 0, Max: 2692][Has Null: f… │
│ tests │ BIGINT │ BitPacking │ [Min: 1, Max: 1058][Has Null: f… │
│ devices │ BIGINT │ BitPacking │ [Min: 1, Max: 186][Has Null: fa… │
│ filename │ VARCHAR │ Dictionary │ [Min: 2022-10-, Max: 2022-10-, … │
└─────────────┴──────────────┴─────────────┴───────────────────────────────────┘
Data Enrichment
I'll launch DuckDB with the newly built database, add three columns for zoom levels 7, 8 and 9 and then bake hexagon values from the tile column's geometry.
$ duckdb ~/ookla.duckdb
ALTER TABLE mobile_perf ADD COLUMN h3_7 VARCHAR(15);
ALTER TABLE mobile_perf ADD COLUMN h3_8 VARCHAR(15);
ALTER TABLE mobile_perf ADD COLUMN h3_9 VARCHAR(15);
UPDATE mobile_perf
SET h3_7 =
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
7)::bigint),
h3_8 =
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
8)::bigint),
h3_9 =
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
9)::bigint);
Below is an example enriched record.
.mode line
SELECT h3_7,
h3_8,
h3_9,
tile
FROM mobile_perf
LIMIT 1;
h3_7 = 8730e0ae9ffffff
h3_8 = 8830e0ae9dfffff
h3_9 = 8930e0ae9d3ffff
tile = POLYGON((126.837158203125 37.5576424267952, 126.842651367188 37.5576424267952, 126.842651367188 37.5532876459577, 126.837158203125 37.5532876459577, 126.837158203125 37.5576424267952))
When I attempted the above on a 4-core, e2-standard-4 GCP VM, I left the job to run overnight and it hadn't finished when I checked up on it in the morning. I later ran the above on a 16-core, e2-standard-16 GCP VM and the 15.7M records were enriched in 2 minutes and 21 seconds. RAM usage had a high watermark of ~7 GB. I've flagged this with Isaac to see if there are any obvious fixes that could be made.
Some database engines are able to produce new tables faster than altering existing ones. I haven't found this to be the case with DuckDB. The following was significantly slower than the above.
CREATE TABLE mobile_perf2 AS
SELECT quadkey,
tile,
avg_d_kbps,
avg_u_kbps,
avg_lat_ms,
tests,
devices,
filename,
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
7)::bigint) h3_7,
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
8)::bigint) h3_8,
printf('%x',
h3_latlng_to_cell(
ST_Y(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
ST_X(ST_CENTROID(ST_GEOMFROMTEXT(tile))),
9)::bigint) h3_9
FROM mobile_perf;
Exporting CSV
The following produces a GZIP-compressed CSV of the mobile_perf table's contents. This was done on a version of the table that didn't contain the hexagons from the above enrichment.
$ echo "COPY (SELECT *
FROM mobile_perf)
TO 'mobile_perf.csv.gz'
WITH (HEADER 1,
COMPRESSION gzip);" \
| duckdb ~/ookla.duckdb
Keep in mind, only one process can use DuckDB in write mode at any one time and the above operation requires write mode. If you see something like the following, you'll need to wait for the other process using the database first.
Error: unable to open database "/home/mark/mobile_perf.duckdb": IO Error: Could not set lock on file "/home/mark/mobile_perf.duckdb": Resource temporarily unavailable
If you're producing a file for mass distribution it might be worth re-compressing the above with pigz. Its compression level is configurable, it can take advantage of multiple cores and produces smaller files than GNU GZIP.
The following finished 1.12x quicker than above with a file that's 2.5 MB smaller.
$ echo ".mode csv
SELECT *
FROM mobile_perf;" \
| duckdb ~/ookla.duckdb \
| pigz -9 \
> mobile_perf.csv.gz
If filesize isn't such a concern, using -1 will produce a file 1.6x faster that's only that is 1.25x larger.
Field order and sort keys have a large impact on GZIP's ability to compress. With 8 fields there are 40,320 field order permutations so trying to find the most compressible will take an excessive amount of time. That said, re-ordering rows by each column and seeing which compresses the most can be done reasonably quickly.
$ COLUMNS=`echo ".mode list
SELECT column_name
FROM information_schema.columns
WHERE table_name = 'mobile_perf';" \
| duckdb ~/ookla.duckdb \
| tail -n +2`
$ for COL in $COLUMNS; do
echo $COL
echo "COPY (SELECT *
FROM mobile_perf
ORDER BY $COL)
TO 'mobile_perf.$COL.csv.gz'
WITH (HEADER 1,
COMPRESSION gzip);" \
| duckdb ~/ookla.duckdb
done
The above needs write access to the database so I'll execute the commands sequentially rather than in parallel with xargs.
DuckDB is able to use multiple cores for most of the above work but certain tasks need to run sequentially on a single core. It might be worth duplicating the original DuckDB database and testing each sort key against its own database if you want to make the most of the CPU cores available to you.
Sorting by avg_u_kbps produced an 841 MB GZIP-compressed CSV file while sorting by quadkey produced a 352 MB file.
The above required just about the entirety of the 16 GB of RAM I had available on this system. Keep this in mind for larger datasets and/or RAM-constrained environments.
ZStandard is a newer lossless compressor that should be able to compress as well as GZIP but ~3-6x faster. I cover it in more detail in my Minimalist Guide to Lossless Compression. If the consumers of your data can open ZStandard-compressed files, it'll be much quicker to produce.
The following finished 3.4x faster than its GZIP counterpart while producing an output ~6% larger.
$ echo "COPY (SELECT *
FROM mobile_perf)
TO 'mobile_perf.csv.zstd'
WITH (HEADER 1,
COMPRESSION zstd);" \
| duckdb ~/ookla.duckdb
Again, if the above was sorted by avg_u_kbps a 742 MB ZStandard-compressed CSV file would be produced and sorting by quadkey produces a 367 MB file.
Exporting Parquet
My Faster PostgreSQL To BigQuery Transfers blog post discussed converting Microsoft's Buildings 130M-record, GeoJSON dataset into a Snappy-compressed Parquet file. In that post, ClickHouse was 1.38x faster at this task than its nearest competitor. I've since run the same workload through DuckDB.
Using an external SSD drive on my 2020 Intel-based MacBook Pro, ClickHouse produced the file in 35.243 seconds. After working through optimisations with the DuckDB team, I could run the same workload in 30.826 seconds and, if I was willing to accept eight Parquet files being produced instead of one, that time was brought down to 25.146 seconds. This was the SQL which ran the quickest.
$ echo "COPY (SELECT *
FROM read_ndjson_objects('California.jsonl'))
TO 'cali.duckdb.pq' (FORMAT 'PARQUET',
CODEC 'Snappy',
PER_THREAD_OUTPUT TRUE);" \
| duckdb
Note the use of read_ndjson_objects instead of read_json_objects, this made a serious performance improvement. Also, PER_THREAD_OUTPUT TRUE will produce multiple files. Omit this setting if you want a single Parquet file produced.
But with that said, the same workload running on a Google Cloud e2-highcpu-32 VM with Ubuntu 20 LTS saw ClickHouse outperform DuckDB by 1.44x. Mark Raasveldt speculated there could be further improvements in DuckDB's compression analysis stage so there is a chance we could see the performance gap to ClickHouse decrease in the near future.