In 2022, Microsoft released a worldwide Building Footprints dataset. The polygons for each building were produced using machine learning algorithms that were fed satellite imagery from Airbus, Maxar, Vexcel and IGN FI, the private subsidiary of France's Institut Géographique National.
There have since been 25 refreshes made to this dataset and it now contains 1.4 billion building footprints with tens of millions of height estimates. Below are the areas covered.
This dataset is one of many that feed the Overture Maps buildings dataset. Below are the Microsoft-sourced building footprints for Baghdad in red and in yellow are the OpenStreetMap-sourced buildings Overture used in their July release.

In this post, I'll explore the September 25th release of the Global ML Building Footprints Microsoft published a few weeks ago.
My Workstation
I'm using a 6 GHz Intel Core i9-14900K CPU. It has 8 performance cores and 16 efficiency cores with a total of 32 threads and 32 MB of L2 cache. It has a liquid cooler attached and is housed in a spacious, full-sized, Cooler Master HAF 700 computer case. I've come across videos on YouTube where people have managed to overclock the i9-14900KF to 9.1 GHz.
The system has 96 GB of DDR5 RAM clocked at 6,000 MT/s and a 5th-generation, Crucial T700 4 TB NVMe M.2 SSD which can read at speeds up to 12,400 MB/s. There is a heatsink on the SSD to help keep its temperature down. This is my system's C drive.
The system is powered by a 1,200-watt, fully modular, Corsair Power Supply and is sat on an ASRock Z790 Pro RS Motherboard.
I'm running Ubuntu 22 LTS via Microsoft's Ubuntu for Windows on Windows 11 Pro. In case you're wondering why I don't run a Linux-based desktop as my primary work environment, I'm still using an Nvidia GTX 1080 GPU which has better driver support on Windows and I use ArcGIS Pro from time to time which only supports Windows natively.
Installing Prerequisites
I'll be using Python and a few other tools to help analyse the data in this post.
$ sudo apt update
$ sudo apt install \
jq \
python3-pip \
python3-virtualenv
I'll set up a Python Virtual Environment and install some dependencies.
$ virtualenv ~/.ms
$ source ~/.ms/bin/activate
$ pip install \
pygeotile \
shapely
I'll use DuckDB, along with its H3, JSON, Lindel, Parquet and Spatial extensions, in this post.
$ cd ~
$ wget -c https://github.com/duckdb/duckdb/releases/download/v1.0.0/duckdb_cli-linux-amd64.zip
$ unzip -j duckdb_cli-linux-amd64.zip
$ chmod +x duckdb
$ ~/duckdb
INSTALL h3 FROM community;
INSTALL lindel FROM community;
INSTALL json;
INSTALL parquet;
INSTALL spatial;
I'll set up DuckDB to load every installed extension each time it launches.
$ vi ~/.duckdbrc
.timer on
.width 180
LOAD h3;
LOAD lindel;
LOAD json;
LOAD parquet;
LOAD spatial;
The maps in this post were rendered with QGIS version 3.38.0. QGIS is a desktop application that runs on Windows, macOS and Linux. The application has grown in popularity in recent years and has ~15M application launches from users around the world each month.
I used QGIS' Tile+ plugin to add geospatial context with Esri's World Imagery and CARTO's Basemaps to the maps.
Footprint Metadata
I'll first download a 28,648-row, 6.3 MB, manifest CSV file. This will tell me the URLs of the building datasets as well as their latest publication date and the geography they cover.
$ mkdir -p ~/ms_buildings
$ cd ~/ms_buildings
$ wget https://minedbuildings.blob.core.windows.net/global-buildings/dataset-links.csv
I'll normalise the compressed file sizes into bytes, extract the publication dates from the URLs and convert the quad keys of the areas covered into Well-known Text (WKT) format. The records will be written out as line-delimited JSON.
$ python3
import csv
import json
from pygeotile.tile import Tile
from shapely.geometry import box
with open('dataset-links.json', 'w') as f:
for (location,
quadkey,
url,
size) in csv.reader(open('dataset-links.csv')):
if quadkey == 'QuadKey': # Skip header
continue
if 'KB' in size:
size = int(float(size.replace('KB', '')) * 1024)
elif 'MB' in size:
size = int(float(size.replace('MB', '')) * 1024 * 1024)
elif 'GB' in size:
size = int(float(size.replace('GB', '')) * 1024 * 1024 * 1024)
elif 'B' in size:
size = int(float(size.replace('B', '')))
else:
raise Exception('Unknown size: %s' % size)
b = Tile.from_quad_tree(quadkey).bounds
geom = box(b[0].longitude, b[0].latitude,
b[1].longitude, b[1].latitude).wkt
date = url.split('/')[4]
f.write(json.dumps({
'location': location,
'geom': geom,
'size': size,
'date': date,
'url': url}, sort_keys=True) + '\n')
I'll load the above JSON into a DuckDB table.
$ ~/duckdb dataset-links.duckdb
CREATE OR REPLACE TABLE links AS
SELECT * EXCLUDE(geom),
ST_GEOMFROMTEXT(geom)
FROM READ_JSON('dataset-links.json');
I'll first produce a GeoPackage (GPKG) file of the geographical footprints covered by this dataset along with the other attributes.
COPY (
SELECT * EXCLUDE(geom),
ST_GEOMFROMTEXT(geom)
FROM links
) TO 'dataset-links.gpkg'
WITH (FORMAT GDAL,
DRIVER 'GPKG',
LAYER_CREATION_OPTIONS 'WRITE_BBOX=YES');
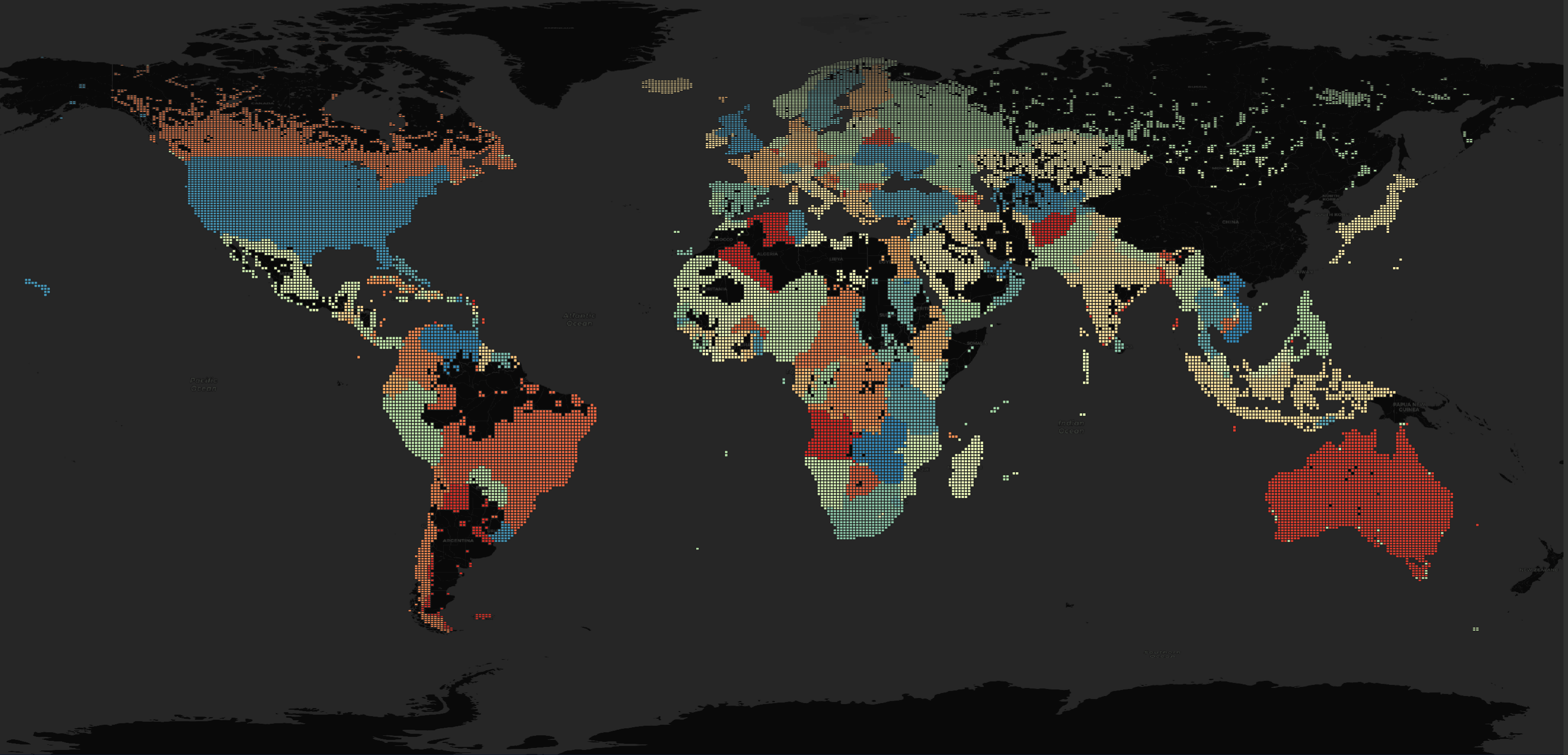
Below are the areas of the world covered by this dataset. I've coloured each region using its name for a colour key.
The first thing I noticed about the above map is that New Zealand, China, North and South Korea, Taiwan, Hong Kong and Macau are all missing.
Below is a closer look at Europe, North Africa and the Middle East.

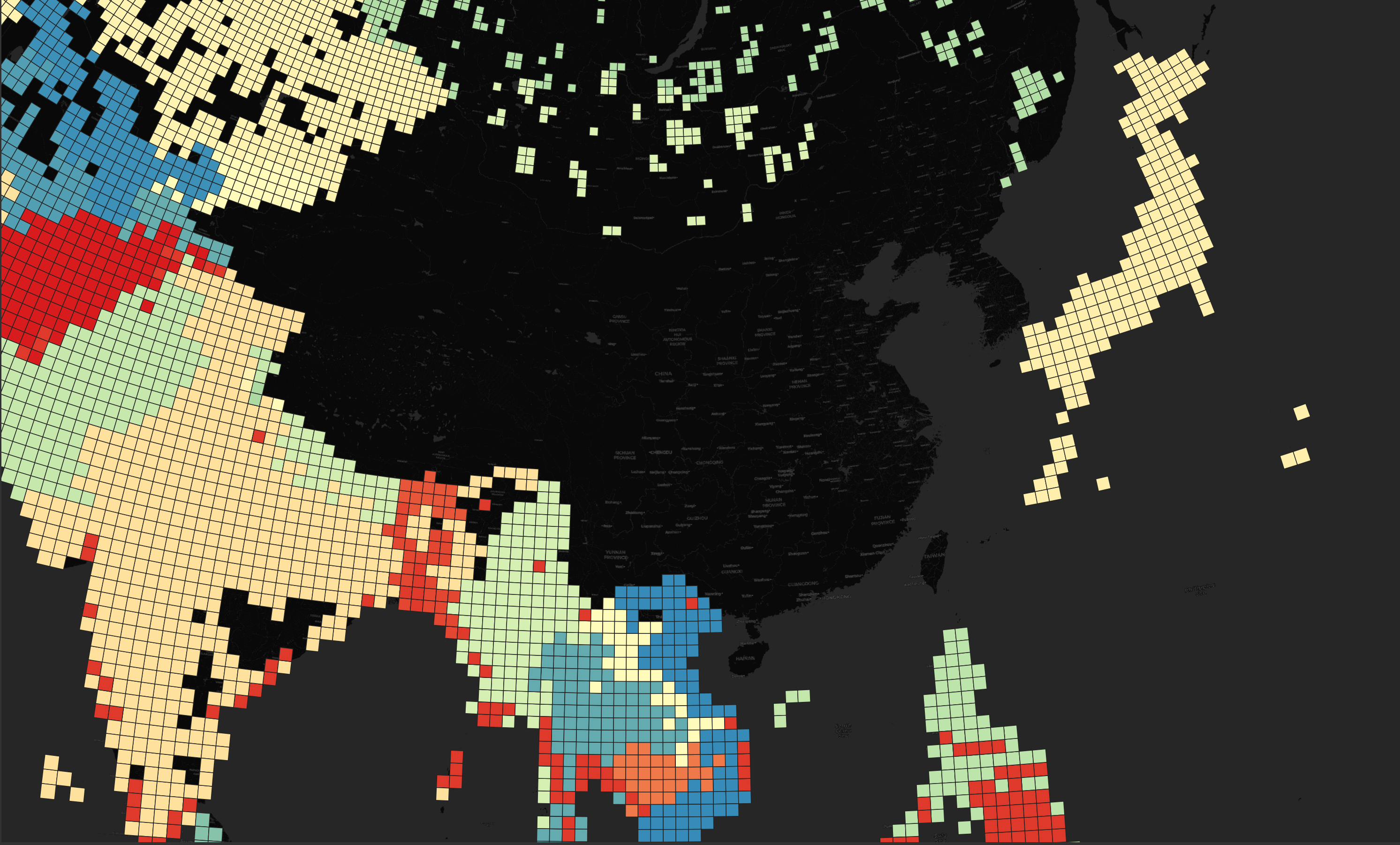
Below is Eastern Asia.
Below is a heat map by file size.

Every URL in the manifest was updated on September 24th.
SELECT date,
COUNT(*)
FROM links
GROUP BY 1
ORDER BY 1; -- All 2024-09-24
There are 224 regions in total in this dataset.
SELECT COUNT(DISTINCT location)
FROM links; -- 224
These are the top ten regions by compressed file size in GB.
SELECT location,
ROUND(SUM(size) / 1024 ** 3, 1) AS GB
FROM links
GROUP BY 1
ORDER BY 2 DESC
LIMIT 25;
┌───────────────┬────────┐
│ location │ GB │
│ varchar │ double │
├───────────────┼────────┤
│ UnitedStates │ 13.2 │
│ India │ 12.6 │
│ Brazil │ 5.5 │
│ Russia │ 5.0 │
│ Indonesia │ 4.6 │
│ Germany │ 3.0 │
│ Japan │ 2.9 │
│ Pakistan │ 2.6 │
│ France │ 2.6 │
│ Nigeria │ 2.3 │
│ Mexico │ 2.1 │
│ UnitedKingdom │ 2.1 │
│ Ukraine │ 2.0 │
│ Vietnam │ 1.8 │
│ Thailand │ 1.8 │
│ SouthAfrica │ 1.7 │
│ Italy │ 1.7 │
│ Turkey │ 1.6 │
│ Bangladesh │ 1.6 │
│ Poland │ 1.4 │
│ Philippines │ 1.2 │
│ Ethiopia │ 1.2 │
│ Kenya │ 1.1 │
│ Australia │ 1.0 │
│ Romania │ 1.0 │
├───────────────┴────────┤
│ 25 rows 2 columns │
└────────────────────────┘
Some regions have been partitioned into more files than their overall size would suggest. Russia has the 4th largest dataset by number of compressed bytes but 2nd by number of files. Svalbard has ~50% more file partitions than Saudi Arabia despite only 2,500 people living there.
SELECT location,
COUNT(DISTINCT url) num_files
FROM links
GROUP BY 1
ORDER BY 2 DESC
LIMIT 25;
┌──────────────────────┬───────────┐
│ location │ num_files │
│ varchar │ int64 │
├──────────────────────┼───────────┤
│ UnitedStates │ 2415 │
│ Russia │ 2309 │
│ Canada │ 2055 │
│ Australia │ 1765 │
│ Brazil │ 1001 │
│ Kazakhstan │ 878 │
│ Asia │ 746 │
│ India │ 667 │
│ Indonesia │ 601 │
│ Europe │ 470 │
│ Norway │ 405 │
│ Svalbard │ 403 │
│ Sweden │ 399 │
│ CongoDRC │ 397 │
│ Finland │ 352 │
│ SouthAfrica │ 320 │
│ Mexico │ 306 │
│ Algeria │ 298 │
│ KingdomofSaudiArabia │ 290 │
│ Ukraine │ 288 │
│ Peru │ 277 │
│ Turkey │ 266 │
│ Argentina │ 253 │
│ Angola │ 253 │
│ Niger │ 253 │
├──────────────────────┴───────────┤
│ 25 rows 2 columns │
└──────────────────────────────────┘
Over 5K files are less than 8 KB in size in this dataset.
SELECT size < 8192 under_8KB,
COUNT(*) num_files
FROM links
GROUP BY 1;
┌───────────┬───────────┐
│ under_8KB │ num_files │
│ boolean │ int64 │
├───────────┼───────────┤
│ false │ 23397 │
│ true │ 5250 │
└───────────┴───────────┘
This is the file count by compressed file size to the nearest 10 MB.
SELECT (ROUND(size / 1024 / 1024 / 1024, 2) * 1000)::INT MB,
COUNT(*) num_files
FROM links
GROUP BY 1
ORDER BY 1;
┌───────┬───────────┐
│ MB │ num_files │
│ int32 │ int64 │
├───────┼───────────┤
│ 0 │ 23189 │
│ 10 │ 3522 │
│ 20 │ 1001 │
│ 30 │ 422 │
│ 40 │ 179 │
│ 50 │ 113 │
│ 60 │ 56 │
│ 70 │ 48 │
│ 80 │ 34 │
│ 90 │ 23 │
│ 100 │ 18 │
│ 110 │ 7 │
│ 120 │ 17 │
│ 130 │ 3 │
│ 140 │ 3 │
│ 150 │ 2 │
│ 160 │ 3 │
│ 170 │ 4 │
│ 180 │ 1 │
│ 190 │ 1 │
│ 290 │ 1 │
├───────┴───────────┤
│ 21 rows │
└───────────────────┘
Japanese Building Footprints
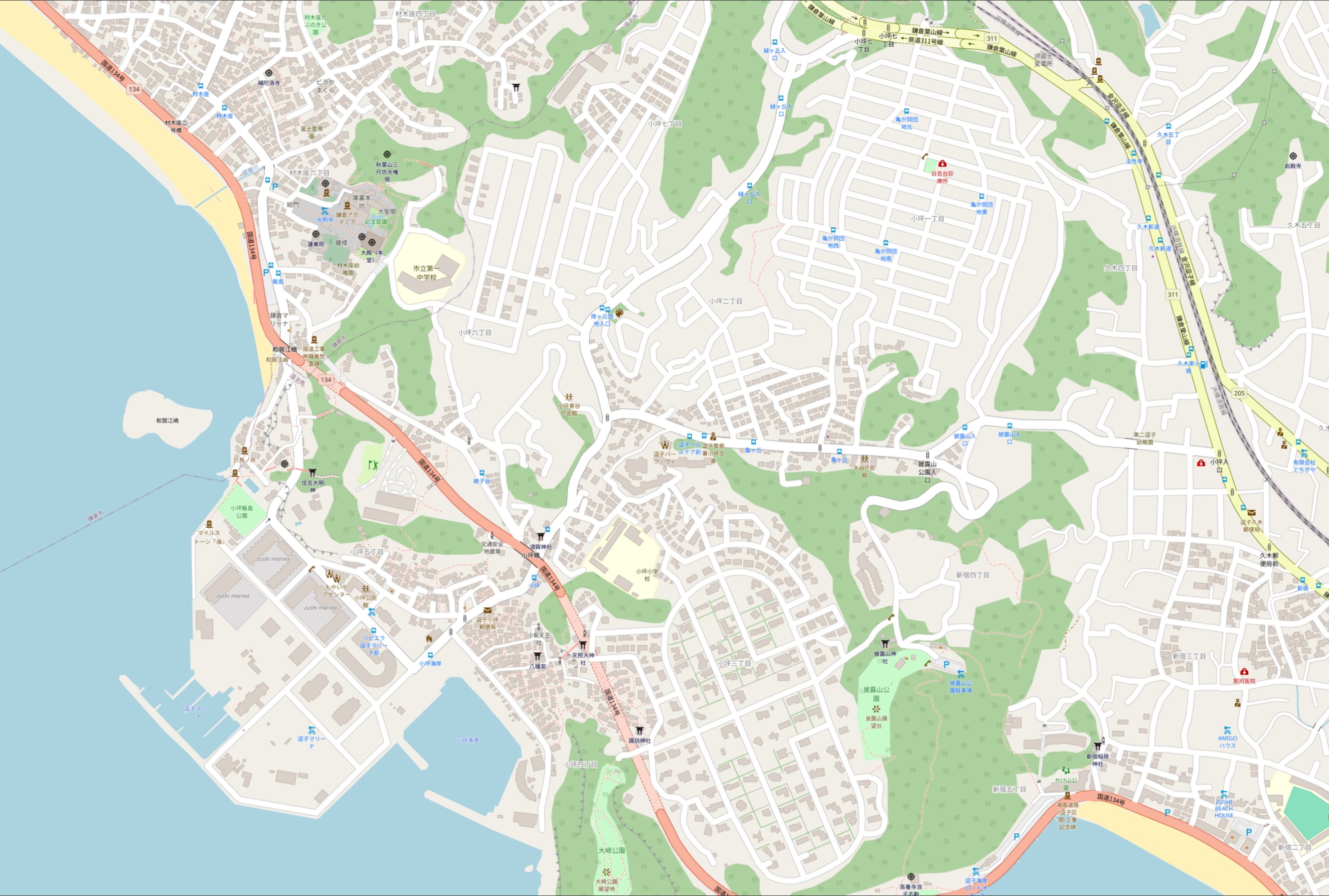
I recently reviewed a number of datasets covering Japanese building footprints. In that post, I couldn't find any one dataset that had building footprints for Zushi. A town an hour's drive south of Central Tokyo. I'll see if this refreshed dataset has been added yet.
Below I'll extract the Japanese Building URLs and download them.
$ cat dataset-links.csv \
| ~/duckdb \
-json \
-c "SELECT Url
FROM READ_CSV('/dev/stdin')
WHERE Location = 'Japan'" \
| jq '.[].Url' \
> japan.txt
$ cat japan.txt | xargs -P4 -I% wget -c %
There are 136 files totalling 2.6 GB compressed.
$ ls *.gz | wc -l # 136
$ du -hs --total *.gz | tail -n1 # 2.6 GB
The filenames suggest they're CSV files but they're actually JSON.
$ gunzip -c part-00199-eabb3dd8-62fd-4d80-9034-66c6a70f8018.c000.csv.gz \
| head -n1 \
| jq -S .
{
"geometry": {
"coordinates": [
[
[
138.2107848183489,
37.82131604929108
],
[
138.2108091058343,
37.82125419905713
],
[
138.21085559565432,
37.821265587790506
],
[
138.2108313081689,
37.82132743801494
],
[
138.2107848183489,
37.82131604929108
]
]
],
"type": "Polygon"
},
"properties": {
"confidence": -1,
"height": -1
},
"type": "Feature"
}
Some files complain of "trailing garbage" when decompressed.
$ for FILENAME in *.csv.gz; do
echo $FILENAME, `gunzip -c $FILENAME | wc -l`
done
part-00001-eabb3dd8-62fd-4d80-9034-66c6a70f8018.c000.csv.gz, 5739
part-00002-eabb3dd8-62fd-4d80-9034-66c6a70f8018.c000.csv.gz, 9600
gzip: part-00003-eabb3dd8-62fd-4d80-9034-66c6a70f8018.c000.csv.gz: decompression OK, trailing garbage ignored
part-00003-eabb3dd8-62fd-4d80-9034-66c6a70f8018.c000.csv.gz, 82319
gzip: part-00005-eabb3dd8-62fd-4d80-9034-66c6a70f8018.c000.csv.gz: decompression OK, trailing garbage ignored
part-00005-eabb3dd8-62fd-4d80-9034-66c6a70f8018.c000.csv.gz, 58161
gzip: part-00006-eabb3dd8-62fd-4d80-9034-66c6a70f8018.c000.csv.gz: decompression OK, trailing garbage ignored
...
I'll create a table in DuckDB for the building data.
$ ~/duckdb buildings.duckdb
CREATE OR REPLACE TABLE buildings (
height DOUBLE,
confidence DOUBLE,
geom GEOMETRY);
I'll decompress and re-compress each GZIP file before importing it into DuckDB. This way the decompression issue is handled before DuckDB is involved.
$ for FILENAME in *.csv.gz; do
gunzip -c $FILENAME \
| gzip -1 \
> working.jsonl.gz
echo "INSERT INTO buildings
SELECT properties.height,
properties.confidence,
ST_GEOMFROMGEOJSON(geometry) geom
FROM READ_NDJSON('working.jsonl.gz')" \
| ~/duckdb buildings.duckdb
done
The above imported 23,846,955 rows of data.
$ ~/duckdb buildings.duckdb
Every confidence level for the Japanese data is -1.
SELECT confidence,
COUNT(*) num_buildings
FROM buildings
GROUP BY 1
ORDER BY 1;
┌────────────┬───────────────┐
│ confidence │ num_buildings │
│ double │ int64 │
├────────────┼───────────────┤
│ -1.0 │ 23846955 │
└────────────┴───────────────┘
The building heights are all -1 as well.
SELECT height,
COUNT(*) num_buildings
FROM buildings
GROUP BY 1
ORDER BY 1;
┌────────┬───────────────┐
│ height │ num_buildings │
│ double │ int64 │
├────────┼───────────────┤
│ -1.0 │ 23846955 │
└────────┴───────────────┘
I'll export these building footprints as a spatially-sorted, ZStandard-compressed Parquet file.
If there isn't a lot of data, GeoPackage (GPKG) files can be dropped right onto QGIS and are convenient to open and work with.
But given there are millions of records, it'll take DuckDB two orders of magnitude longer to produce a GPKG file versus a Parquet file. QGIS don't yet support drag-and-drop for Parquet files but going through a UI dialog to import them is worth the time saved producing the file in the first place.
COPY(
SELECT height,
confidence,
ST_ASWKB(geom) AS geom
FROM buildings
WHERE ST_Y(ST_CENTROID(geom)) IS NOT NULL
AND ST_X(ST_CENTROID(geom)) IS NOT NULL
ORDER BY HILBERT_ENCODE([ST_Y(ST_CENTROID(geom)),
ST_X(ST_CENTROID(geom))]::double[2])
) TO 'japan.pq' (
FORMAT 'PARQUET',
CODEC 'ZSTD',
ROW_GROUP_SIZE 15000);
The resulting Parquet file is 1.5 GB in size.
Below is a rendering of Zushi, Japan and the surrounding area. There aren't any building footprint predictions for that area. I raised an issue over this.

OpenStreetMap is also still missing any building footprints for the area as well.
Ship Parquet, not CSVs
It would be good to see Microsoft migrate from shipping CSVs and line-delimited GeoJSON to spatially-sorted, ZStandard-compressed Parquet files. Their building footprints dataset is relatively new and is probably intended for technical audience. A lot of bandwidth, storage and engineering time could be saved by this.
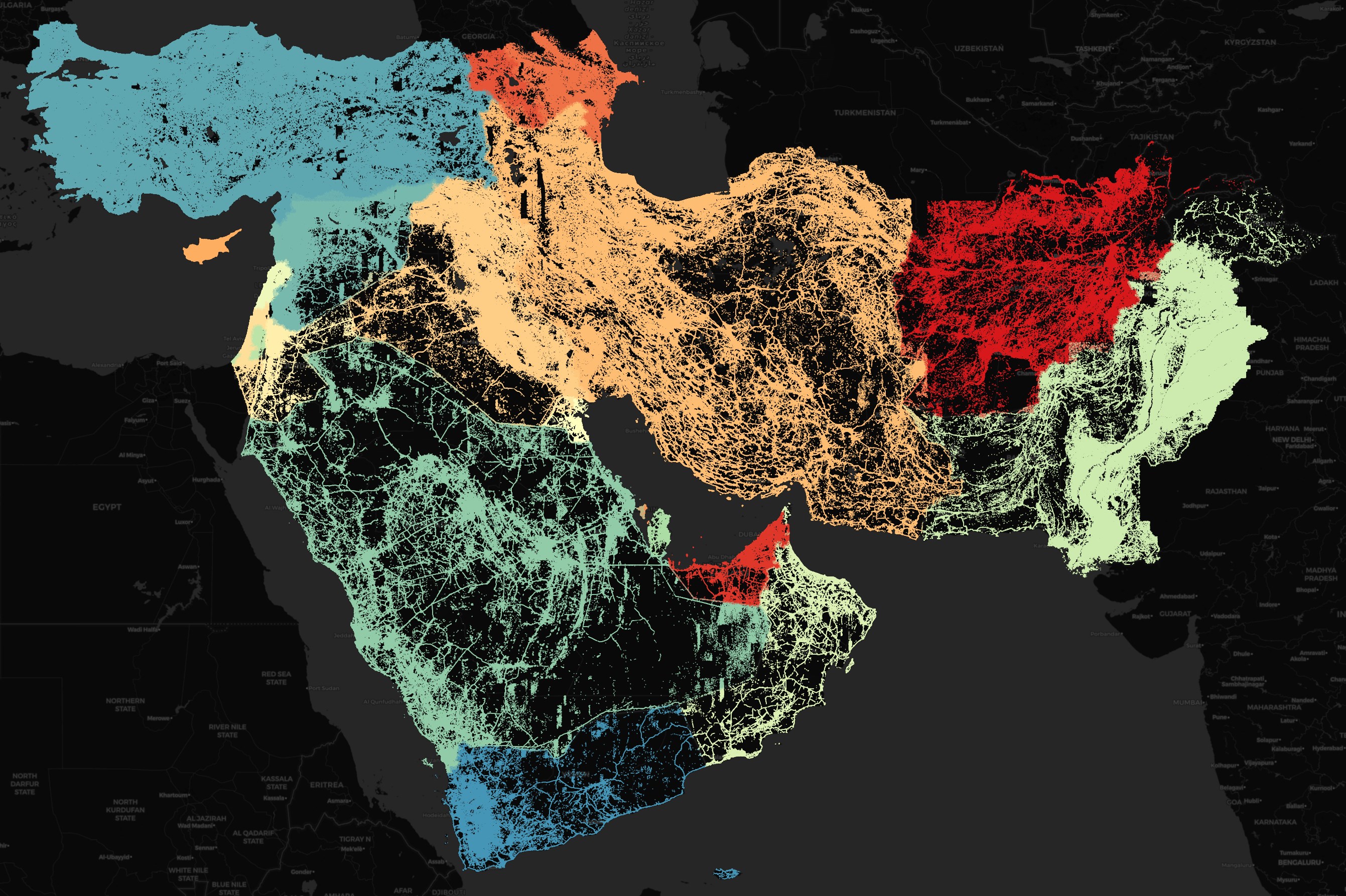
Microsoft also has a counterpart ML roads dataset. Their Middle East deliverable is shipped as an 804 MB ZIP file containing 3.6 GB of tab-separated data with the geometry field being in GeoJSON. The dataset is only 391 MB when converted into a spatially-sorted, ZStandard-compressed Parquet file.
$ wget https://usaminedroads.blob.core.windows.net/road-detections/MiddleEast-Full.zip
$ unzip MiddleEast-Full.zip
$ ~/duckdb roads.duckdb
CREATE OR REPLACE TABLE roads AS
SELECT column0 AS iso2,
ST_GEOMFROMGEOJSON(column1::JSON->'$.geometry') geom
FROM READ_CSV('MiddleEast-Full.tsv',
header=false)
ORDER BY HILBERT_ENCODE([ST_Y(ST_CENTROID(geom)),
ST_X(ST_CENTROID(geom))]::double[2]);
COPY(
SELECT iso2,
ST_ASWKB(geom) AS geom
FROM roads
) TO 'MiddleEast-Full.pq' (
FORMAT 'PARQUET',
CODEC 'ZSTD',
COMPRESSION_LEVEL 22,
ROW_GROUP_SIZE 15000);
Below is a rendering of their roads dataset. This only took about a minute to load into QGIS.